The indexer is an interactive application. Users should be able to:
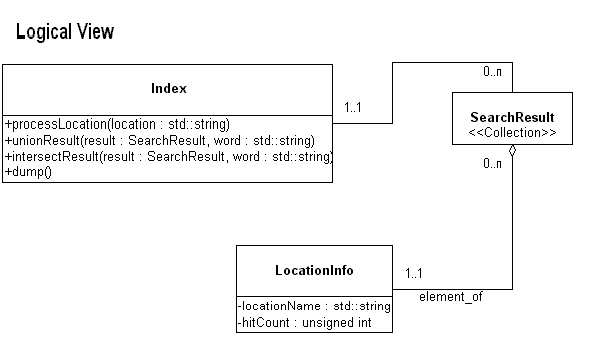
Here is a suggested design:
In this design, the index is maintained by the Index object. It populates SearchResult objects, which are basically some kind of Collection in the STL sense. (In other words, SearchResult may be a class name for a user-defined Collection, or it may be just a typedef for some STL collection.) SearchResult contains multiple LocationInfo objects, each of which contains the name of a location (or file) and a hit count for that search.
Create and run unit tests for your classes that don't require interactive input. Use these to test the indexer at each step as you create it. Turn in the unit test code and results along with your interactive sessions.
You may want to create some additional member functions to make unit testing easier. Below is a sample which uses the unit test framework published in the recent C/C++ User's Journal ( ftp://ftp.cuj.com/pub/2000/1809/allison.zip ):
...
class Indexer
{
public:
// Process a file/location, adding all the words
// found to the index:
void processLocation(std::string const &filename);
// Add a single word to the index. Location
of
// word is recorded along with the count.
void addWord(std::string const &word,
std::string const &location);
// Narrow a search result by adding another word.
// Resulting (modified) collection contains only
// locations that contain both words.
// The new occurrence count for each location is
equal to the
// minimum of the original and the new counts.
void intersectResult(SearchResult &result, std::string
const &word);
// Broaden a search result by adding another word.
// Resulting (modified) collection will have
// all locations that contain either word.
// For locations that contain both words, the
// occurrence count is equal to the maximum of
// the two individual word counts.
void unionResult(SearchResult &result, std::string
const &word);
// Remove locations that contain the given word
from the
// result set. (Not required.)
void subtractResult(std::string const &word, WordInfoColl
&result);
// Print out contents of index for debugging.
void dump() const;
private:
...
};
...
class IndexerTest : public Test
{
Index idx;
public:
IndexerTest() {
setStream(&cerr);
}
void run() {
// Add a single word and
see if we get
// it back when we search:
idx.addWord("hello","hellogoodbye.txt");
SearchResult s;
idx.unionResult(s,"hello");
_test(s.size()==1);
_test(s.begin()->first
== "hellogoodbye.txt");
// Add a new document with
the same word
// and test that we get back
two results:
s.clear();
idx.addWord("hello","hello.txt");
idx.unionResult(s,"hello");
_test(s.size()==2);
// Increase the word count
for a single document
// and ensure that we still
get back two documents:
s.clear();
idx.addWord("hello","hello.txt");
idx.unionResult(s,"hello");
_test(s.size()==2);
// Add a couple more words
and inspect index contents:
idx.addWord("goodbye","hellogoodbye.txt");
idx.addWord("hello","hellogoodbye.txt");
idx.dump();
// Look for document that
contains
// both "hello" and "goodbye";
this
// should be just hellogoodbye.txt:
s.clear();
idx.unionResult(s,"hello");
idx.intersectResult(s,"goodbye");
_test(s.size()==1);
_test(s.begin()->first
== "hellogoodbye.txt");
_test(s.begin()->second.hitCount
== 1);
// Intersect with word
"boffo" which
// is not in index:
idx.intersectResult("boffo",s);
_test(s.size()==0);
// Also need to test document
file interface!
}
};
int main()
{
Suite s("Suite Test");
// Catch null test:
s.addTest(new IndexerTest);
s.run();
long fails = s.report();
cout << "There were " << fails <<
" failures." << endl;
cout << (fails ? "FAILURE!" : "SUCCESS!") <<
endl;
}
You can download test files here.